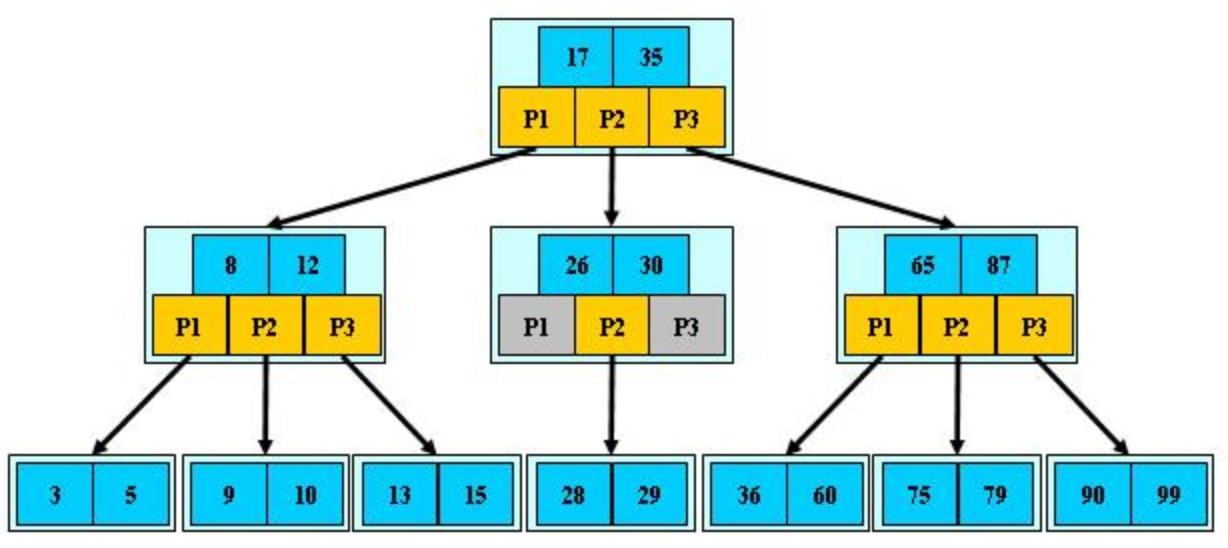
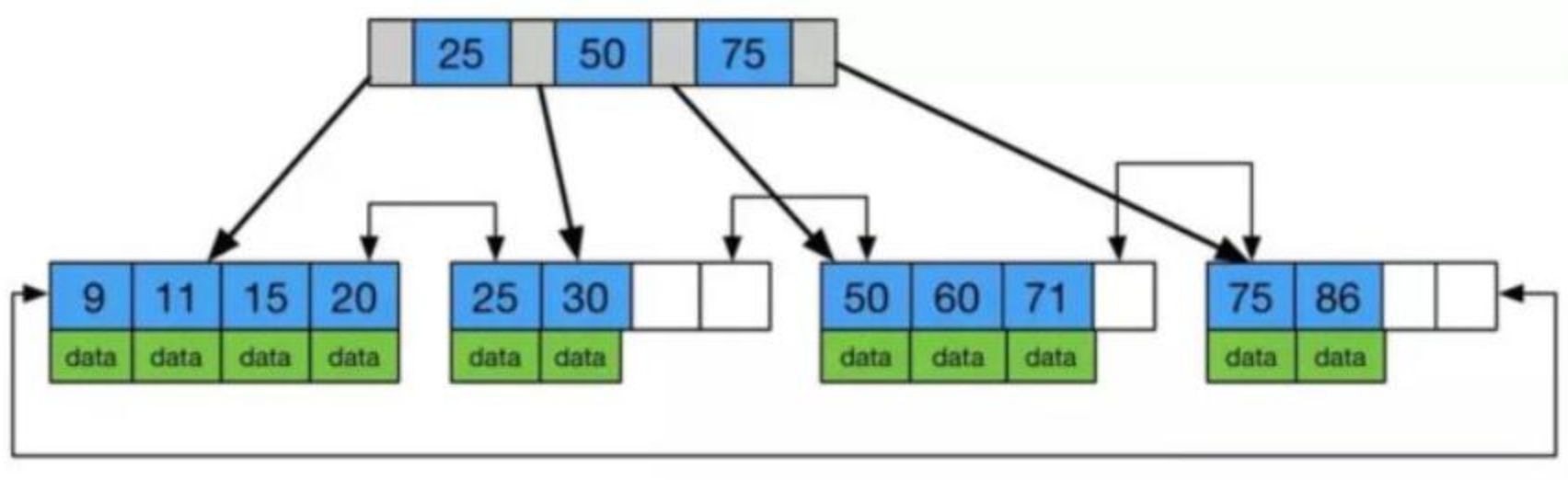
1)首先两种数据库都选择平衡m叉树作为底层索引结构,因为平衡树m叉树是同种元素序列情况下的深度最小的m叉排序树。这可以减少m叉树元素查找的深度,从而提升平均查找效率。B树和B+树都是平衡m叉树。Mongodb选择B树为索引结构 Mysql是典型的关系型数据库,选择B+树
其实这最本质的原因我个人认为是数据库类型的原因,Mysql是关系型数据库,遍历操作多,比如left join之类的,自然选择具有数据前后关系的B+树;Mongodb是非关系型数据库,遍历操作少,就选择B树,因为单次查询用中序遍历,可以直接查到符合的数据。
Mongodb是非关系型数据库(nosql ),属于文档型数据库。文档是mongoDB中数据的基本单元,类似关系数据库的行,多个键值对有序地放置在一起便是文档,语法有点类似javascript面向对象的查询语言,它是一个面向集合的,模式自由的文档型数据库。
1.如果需要将mongodb作为后端db来代替mysql使用,即这里mysql与mongodb 属于平行级别,那么,这样的使用可能有以下几种情况的考量: (1)mongodb所负责部分以文档形式存储,能够有较好的代码亲和性,json格式的直接写入方便。(如日志之类) (2)从datamodels设计阶段就将原子性考虑于其中,无需事务之类的辅助。开发用如nodejs之类的语言来进行开发,对开发比较方便。 (3)mongodb本身的failover机制,无需使用如MHA之类的方式实现。
2.将mongodb作为类似redis ,memcache来做缓存db,为mysql提供服务,或是后端日志收集分析。 考虑到mongodb属于nosql型数据库,sql语句与数据结构不如mysql那么亲和 ,也会有很多时候将mongodb做为辅助mysql而使用的类redis memcache 之类的缓存db来使用。 亦或是仅作日志收集分析。
索引是影响数据库性能的重要元素.
这里比较一下 MySQL 与 MongoDB 中索引的基本使用, 也算复习一下这个数据库中的基本概念
注: MongoDB 的操作以其自带 mongoshell 为准, 不同语言的 api 操作(传参, 调用)可能会有一些差别
准备
索引总是建立在字段上的, 所以我们这里做准备一张简单的表, 并做一些简单的数据.
MySQL 怎么建表, 插数据就不多说了
-- 建表
CREATE TABLE tbl (
id int ,
value int ,
PRIMARY KEY ( id )
);
-- 插入5条极简数据
INSERT INTO tbl VALUES ( 1 , 1 ), ( 2 , 2 ), ( 3 , 3 ), ( 4 , 4 ), ( 5 , 5 )
MongoDB 不需要显式的创建 集合 (Collection, 与 MySQL 中表是同一级概念) 所以直接插入数据.
[ 1 , 2 , 3 , 4 , 5 ]. forEach ( function ( v ) {
db . tbl . insert ({ _id : v , value : v });
})
索引的 CRD
### 创建索引.
MySQL 创建索引的方式很多, 可以在建表同时直接创建. 也可以在建表后再补.
如果是在建表同时创建, 需要将上面的建表语句修改一下
CREATE TABLE tbl (
id int ,
value int ,
PRIMARY KEY ( id ), -- 创建主键索引
KEY ( value ) -- 创建一般索引
);
建表后则用 ALTER TABLE 或 CREATE INDEX 创建
下面两种方式均可以在 tbl 表的 value 字段上创建一个名为 idx_value 的索引.
-- ALFTER TABLE 式
ALTER TABLE tbl ADD KEY idx_value ( value );
-- CREATE INDEX 式
CREATE INDEX idx_value ON tbl ( value )
MongoDB 则只留出了一个 createIndex 的接口来创建索引
db . tbl . createIndex ({ value : 1 })
另外要注意的是, MongoDB 允许在暂时不存在的集合或不存在的字段上添加索引.
如果集合名或字段字敲错了, mongoshell 可不会报错.
在 mongoshell 中有一个助手方法, ensureIndex
> db . tbl . ensureIndex
function ( keys , options ){
this . createIndex ( keys , options );
err = this . getDB (). getLastErrorObj ();
if ( err . err ) {
return err ;
}
// nothing returned on success
}
可以看到, 其实 ensureIndex 仍然通过调用 createIndex 来完成索引创建
其实像 nodejs 或 python 中 MongoDB 的建立索引的接口名称都使用的 ensure. 而不是 create
查看已有索引.
MySQL 使用 show index 命令即可查看, 同时可以使用 where 子句进行过滤
SHOW INDEX FROM tbl WHERE KEY_NAME = 'idx_value' ;
MongoDB 则不能进行条件过滤, 只能使用 getIndexes 查看所有的索引信息.
删除索引.
在 MySQL 中删除索引时, 和创建一样可以用 ALTER TABLE 或 DROP INDEX 两种方法
-- ALTER TABLE 式
ALTER TABLE tbl DROP INDEX idx_value ;
-- DROP INDEX 式
DROP INDEX idx_value ON tbl ;
而 MongoDB 则是允许用 dropIndexes 一次性删除全部索引, 也可以用 dropIndex 删除指定索引
// 删除全部索引
db . tbl . dropIndexes ();
// 通过索引字段删除指定索引
db . tbl . dropIndex ({ value : 1 });
// 通过索引名称删除指定索引
db . tbl . dropIndex ( 'value_1' );
索引在执行计划中的表现
### 没有使用索引的情况 先来看看没有使用索引时的执行计划是个什么样子.
使用 explain 命令可以获得 MySQL 中 SQL 语句的执行计划.
mysql > explain select * from tbl where value = 1 ;
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
| 1 | SIMPLE | tbl | ALL | NULL | NULL | NULL | NULL | 5 | Using where |
type 字段中的 ALL 就表示了这次查询是全表扫描, 而 key_len 字段则明确的告诉我们没有使用索引
不能相信 key 字段, 因为可能这样: create index `NULL` on tbl(value)
类似的,MongoDB允许使用 explain 方法获取查询的执行计划
> db . tbl . find ({ value : 1 }). explain ();
{
"cursor" : "BasicCursor" ,
"isMultiKey" : false ,
"n" : 1 ,
"nscannedObjects" : 5 ,
"nscanned" : 5
// ... 一些其它字段
}
其中 cursor 的值为 BasicCursor, 已经说明这次查询没有使用索引
一般情况
现在, 把索引建立起来, 看看相同查询的执行计划.
MySQL 使用索引查询时的执行计划
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
| 1 | SIMPLE | tbl | ref | idx_value | idx_value | 5 | const | 1 | Using where |
type 显示为 ref, 说明是在使用一般索引查询( 若使用主键索引, 则显示为 const) rows 字段由之前的 5 变为 1, 扫描行数变少了. key, key_len 说明了使用了什么索引以及这个索引有多长
MongoDB
{
"cursor" : "BtreeCursor value_1" ,
"isMultiKey" : false ,
"n" : 1 ,
"nscannedObjects" : 1 ,
"nscanned" : 1 ,
// 其它字段
}
cursor 值为 BtreeCursor value_1, 表示使用了名为 value_1 的索引进行查询 nscannedObjects 表示最终结果中查询过的对象数, 使用索引之前为 5, 现在变为 1.
仅查询索引
MySQL 和 MongoDB 中都有这样一个特性:
查询时, 如果要求返回的字段信息只包含索引字段, 那么将直接从索引中返回值, 不会再进行实表查找
MySQL 中, 如果出现这样的情况, 会在 Extra 字段中显示 using index 信息, 如下
mysql > explain select value from tbl where value = 1 ;
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
| 1 | SIMPLE | tbl | ref | idx_value | idx_value | 5 | const | 1 | Using where ; Using index |
而 MongoDB 中, 则是将 indexOnly 字段置为 true, 并且 nscannedObjects 为 0
> db . tbl . find ({ value : 1 }, { _id : 0 , value : 1 }). explain ()
{
"cursor" : "BtreeCursor value_1" ,
"isMultiKey" : false ,
"n" : 1 ,
"nscannedObjects" : 0 , // 说明没有扫描实际对象
"nscanned" : 1 ,
"nscannedObjectsAllPlans" : 0 ,
"nscannedAllPlans" : 1 ,
"scanAndOrder" : false ,
"indexOnly" : true , // 说明没有返回字段只包含索引字段
"nYields" : 0 ,
"nChunkSkips" : 0 ,
"millis" : 0 ,
// 其它字段
}
MongoDB中排序使用索引
在 MongoDB 中, 除了查询条件可以利用索引以外, 进行排序的相应字段也可以在排序时利用索引.
这点是 MySQL 所不具备的
直接上执行计划.
> db . tbl . find (). sort ({ value : 1 }). explain ()
{
"cursor" : "BtreeCursor value_1" ,
"isMultiKey" : false ,
"n" : 5 ,
"nscannedObjects" : 5 ,
"nscanned" : 5 ,
"nscannedObjectsAllPlans" : 5 ,
"nscannedAllPlans" : 5 ,
"scanAndOrder" : false ,
"indexOnly" : false ,
"nYields" : 0 ,
"nChunkSkips" : 0 ,
"millis" : 0 ,
"indexBounds" : {
"value" : [
[
{
"$minElement" : 1
},
{
"$maxElement" : 1
}
]
]
},
"server" : "AY14031520284347468cZ:27017"
}
可以看到, 没有任何查询条件, 只进行排序确实是使用了索引.
不同的是, 在 indexBounds 中对索引字段 value 的查找范围是从 $minElement 到 $maxElement.
索引的强制使用
因为数据库自动使用索引的选择不见得是最好的. 所以 MySQL 和 MongoDB 都提供了强制使用索引的方法.
MySQL 中 使用 use index 子句
select * from tbl use index ( idx_value );
MongoDB 中则使用 hint 方法
db . tbl . find (). hint ({ value : 1 });